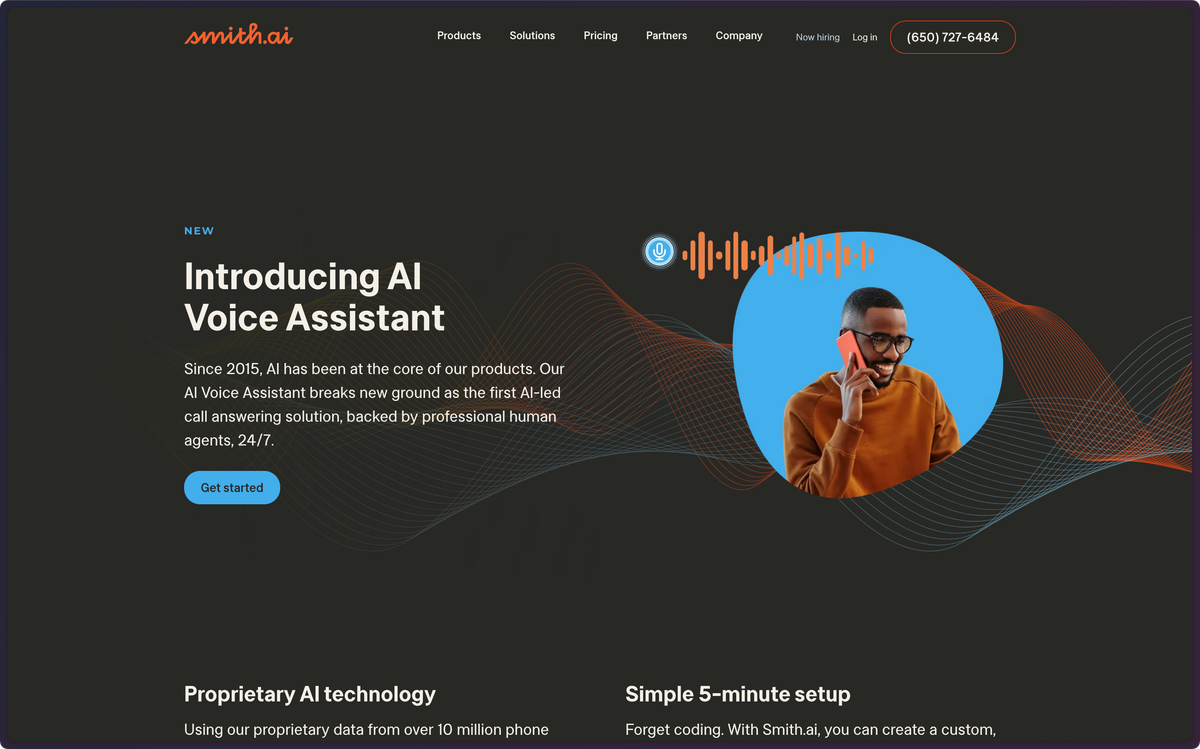
Building the next generation of AI Voice Assisant
I led the project with a Group PM partner to transform our human answering service model into an AI voice assistant. We moved from software assisted, manual setup to a fully-automated, self-service product.
Context
Smith's human answering services handles tens of millions of calls and we wanted to use that knowledge to train an AI to be the best intake and qualification service on the market. We call that "Voice Assistant".
Goals:
- Automate sign-up and configuration
- Demonstrate best-in-class AI voice conversations
- Facilitate product-led growth
My Role
- Partnering with the Group Product Manager to shape the entire experience.
- Break down the full scope into discrete projects
- Managed designers assigned to those projects
- Lead the design for the instructions project
Transitioning to Self-Service
Initially, customers had to go through manual sign-ups and multiple onboarding calls. AI supported only some aspects of the workflow, while humans handled the majority of tasks. Our goal was to automate the process, from sign-up to configuration, allowing customers to create a fully functional voice assistant with minimal intervention. This required a shift in mindset—no longer just a tool for human agents, but a product capable of standing alone, ready to answer business queries immediately upon sign-up.
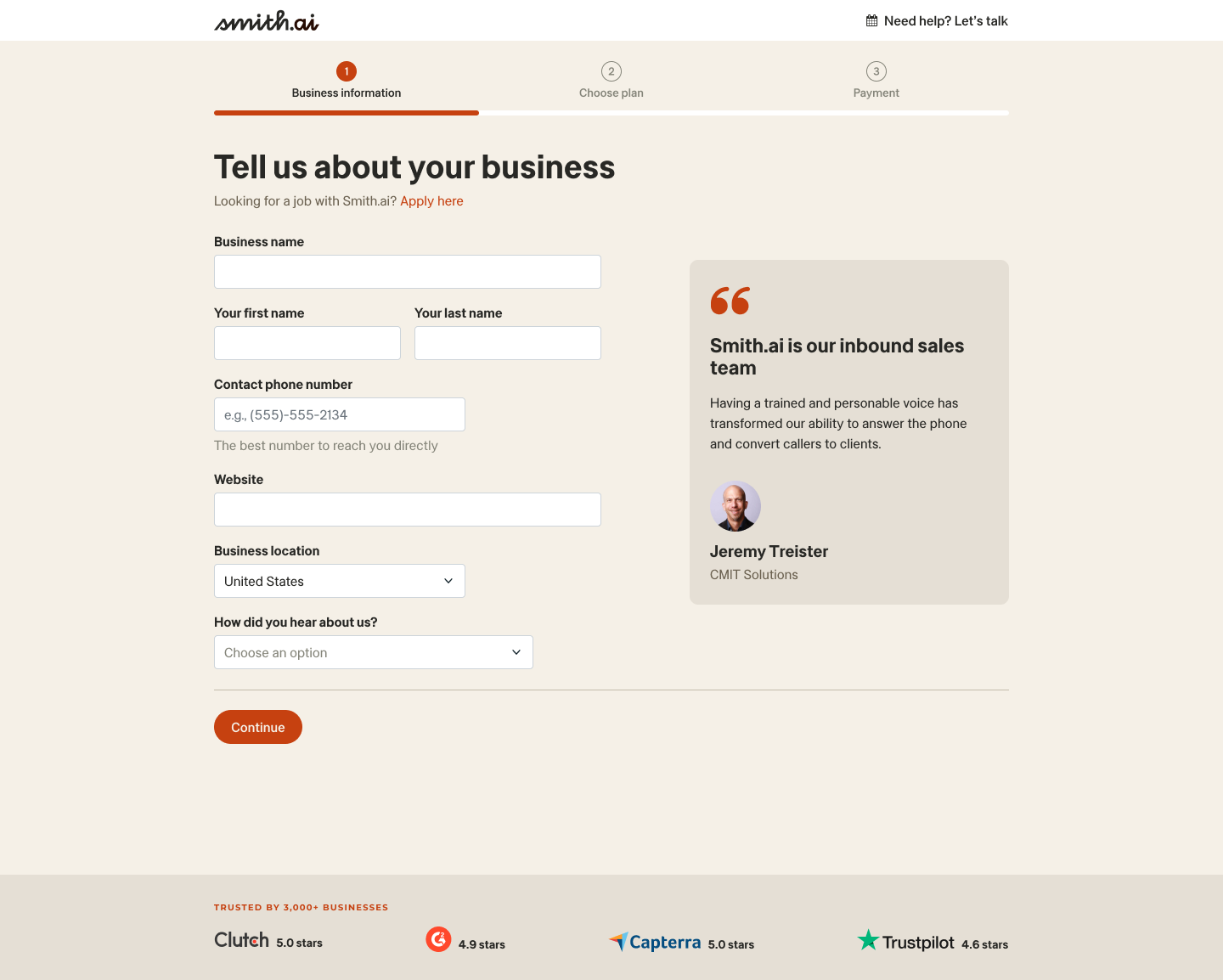
We designed a conversion-optimized flow that would take payments upfront and provide customers with an excellent first-use experience. The challenge was to make everything “just work” without requiring any configuration, allowing the AI assistant to be active immediately upon registration. This meant designing not just a user-friendly interface but also a seamless backend that integrated call transfers, custom responses, and data collection.
Research
We began by studying human conversations in depth. What makes a conversation feel natural and engaging? Concepts like active listening, mirroring, and turn-taking became key elements we aimed to simulate in our AI assistant. We used existing customer interactions and voice call logs to identify patterns of what made conversations successful, as well as areas where AI could fill gaps that were traditionally handled by human agents.
Capability Assessment
It was clear there are some things that AI can't do yet and so we needed to understand the core requirements customers have for an answering service and map that to AI or humans.
The capabilities of the voice assistant needed to cover the following:
- Greet the caller in a natural way and ask how they can help
- Qualify callers based on services that customers have
- Capture additional information from callers (if they are qualified)
- Transfer specific types of calls to customers
One thing the AI is really bad at is pronunciation and spelling, especially when it comes to email addresses. To cover the shortfall in the technology we applied several approaches.
We structured our prompts and conversational flow to ask for clarification of spelling in certain circumstances and have a human agent ready to take over the call if the caller requested for the AI was unable to confidently obtain the information.
Designing Conversations
Designing conversations was a major focus of our development process. We had to ensure that the AI’s responses felt fluid and human-like, while being capable of handling the nuances of business inquiries.
We used a combination of pre-defined prompts, retrieval augmented generation, and context retention to design conversations that flow naturally unlike any other AI voice service.
Predefined prompts give us the ability to set objectives, tone, and guidance for how to handle specific parts of conversations.
Context retention allows us to ask "How can I help you" at the start of a call and use that information to answer questions later in the call; exactly like a human would.
We used a novel approach with retrieval augmented generation where we can dynamically load specific parts of branching conversational logic to prevent overloading the context window and confusing the AI.
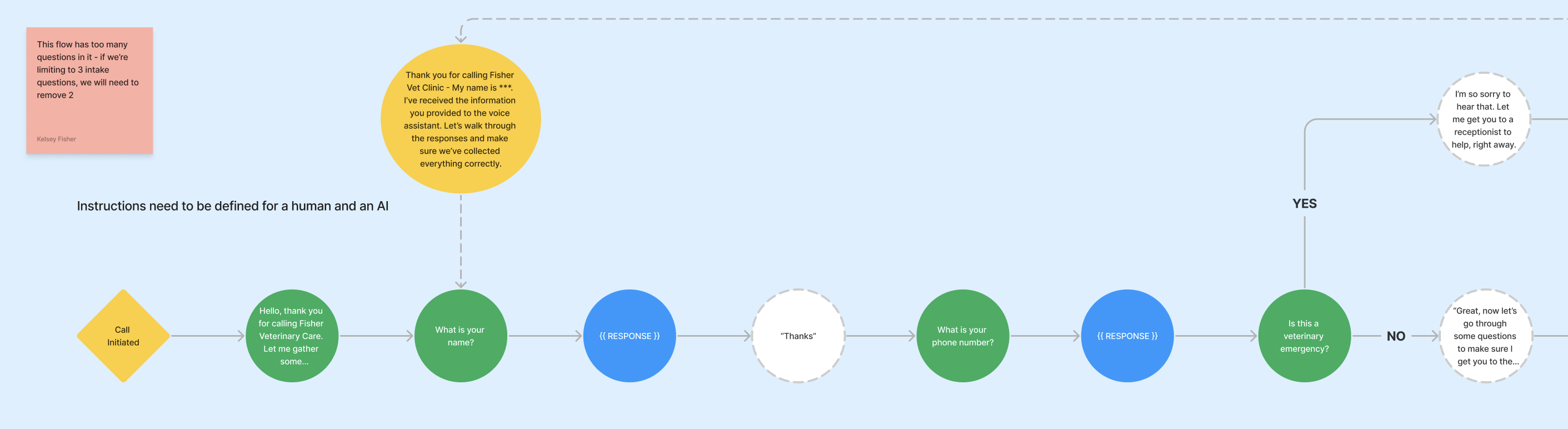
Abstracting the Complex
In the human-assisted service, the system required extensive documentation and manual configurations by humans on both the onboarding and updating sides. Moving to a self-service model meant needing to simplifying the instructions both by artificially limiting the conversational complexity and restricting the controls that are exposed to customers.
The new interface had to represent a complex system in an easy-to-use way, avoiding overwhelming new users.
To achieve this, we opted for a simple linear representation of a conversation. Any branches (such as after being qualified or disqualified) were represented within this structure.
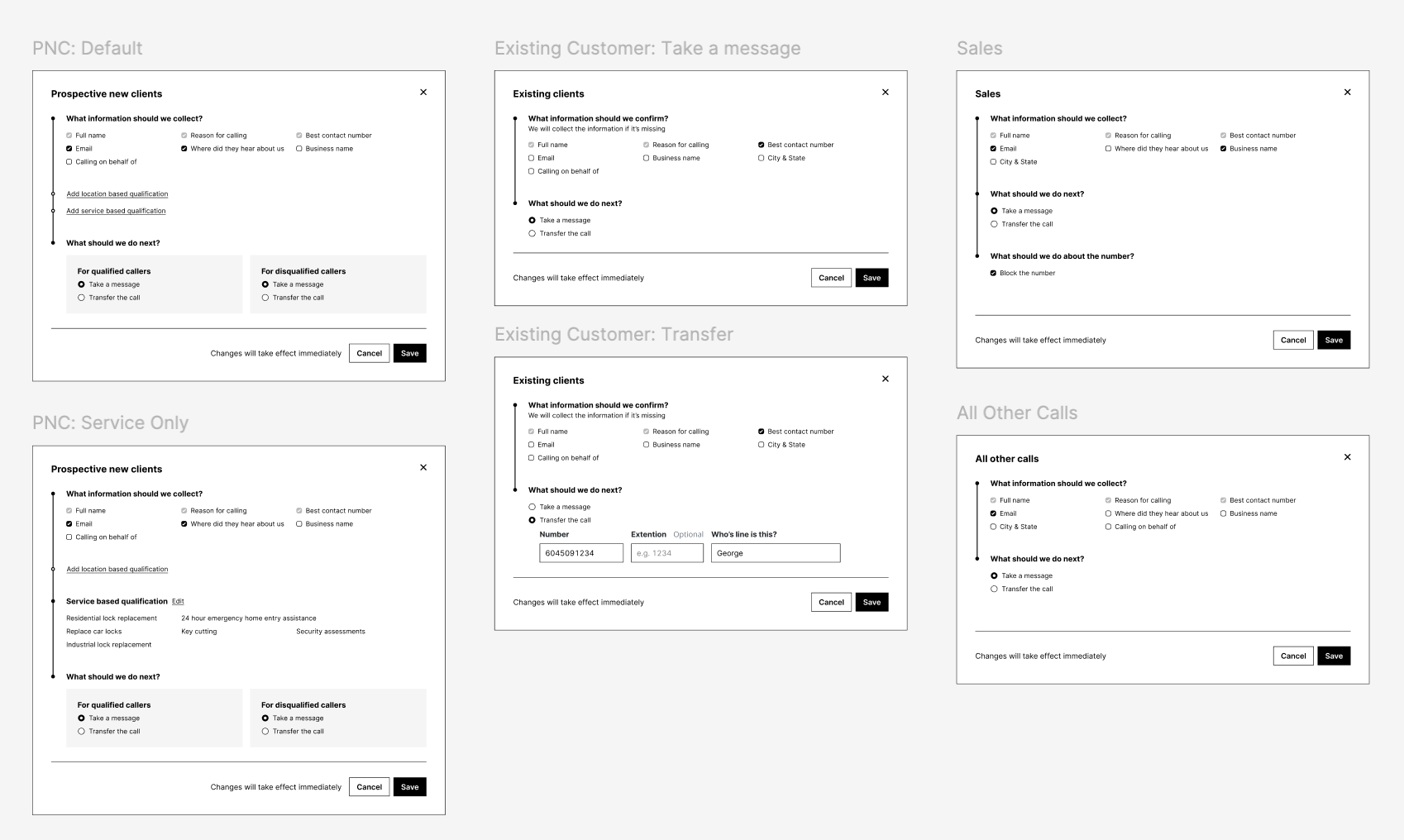
Different types of calls were distilled down to 5 common patterns:
- Potential new clients
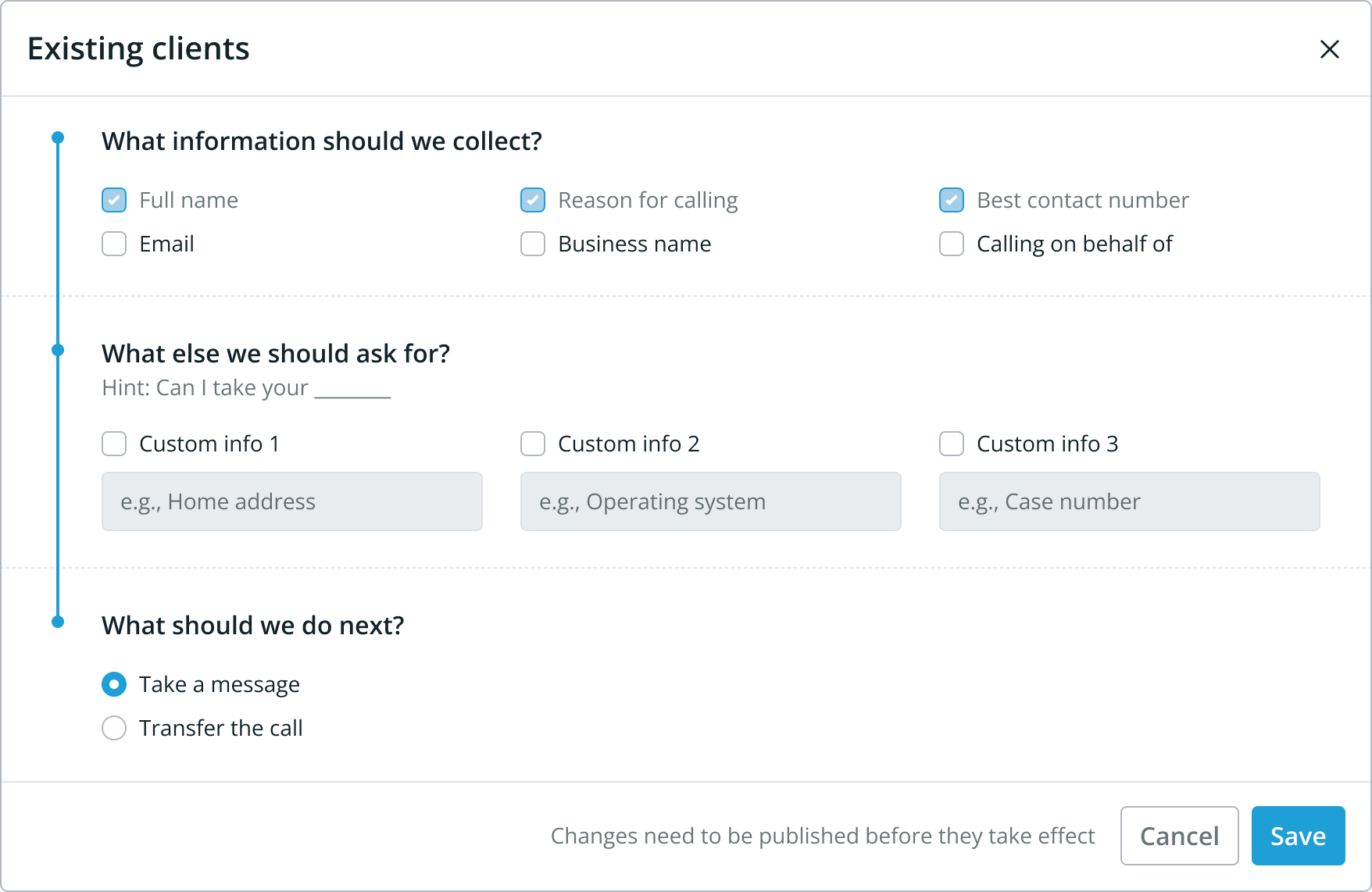
- Existing clients
- Sales
- Spam
- All other calls

Initially, we kept the greeting prescriptive until we understood from customers exactly how they wanted to use the greeting. When we offer a free text field, we need to make sure that "how can I help you?" is still asked to start the conversation as well as respecting call recording disclosure.
Below is the current most complex caller type; Potential new clients.
Iterative design feedback loop
We implemented a structured process to capture and act on customer feedback from various channels like user interviews, sales, and support interactions. By centralising and automating data collection, we reduced the manual effort and ensured that key insights were quickly categorised and prioritised.
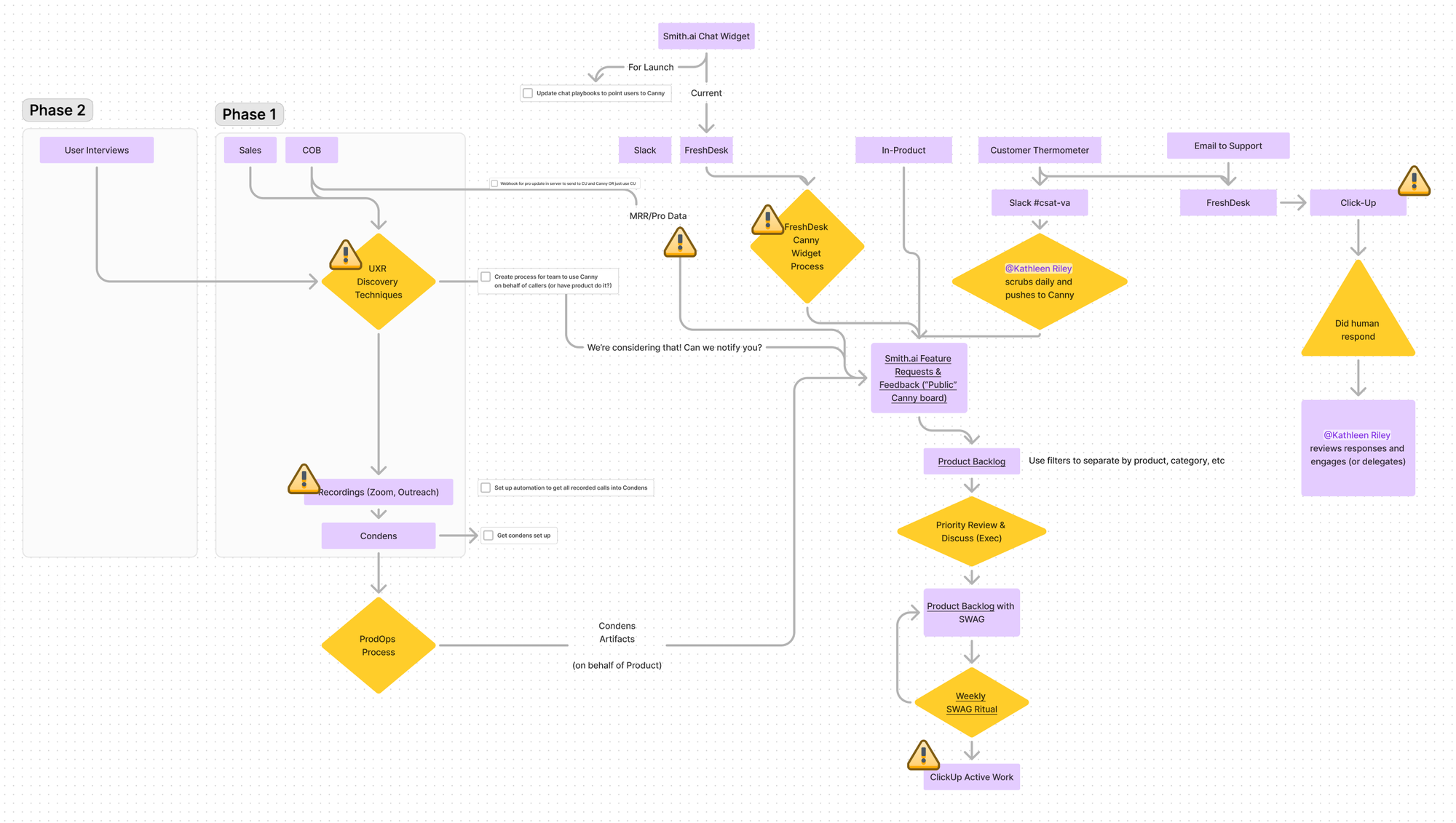
This system ensures that feedback flows seamlessly into the product development process, allowing us to prioritise high-impact changes. Regular reviews ensure that customer input directly informs the roadmap, creating a more responsive, user-focused development cycle.
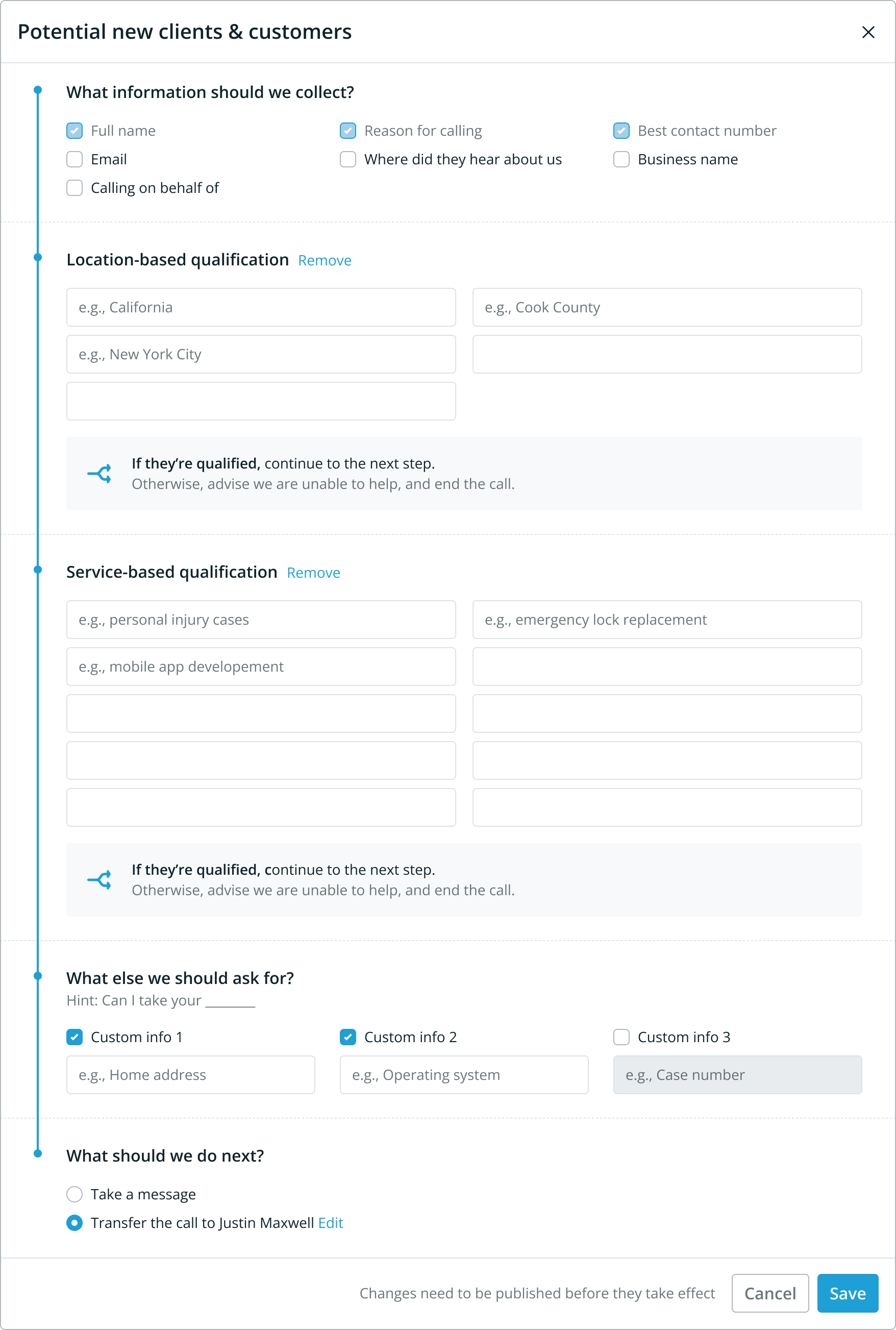
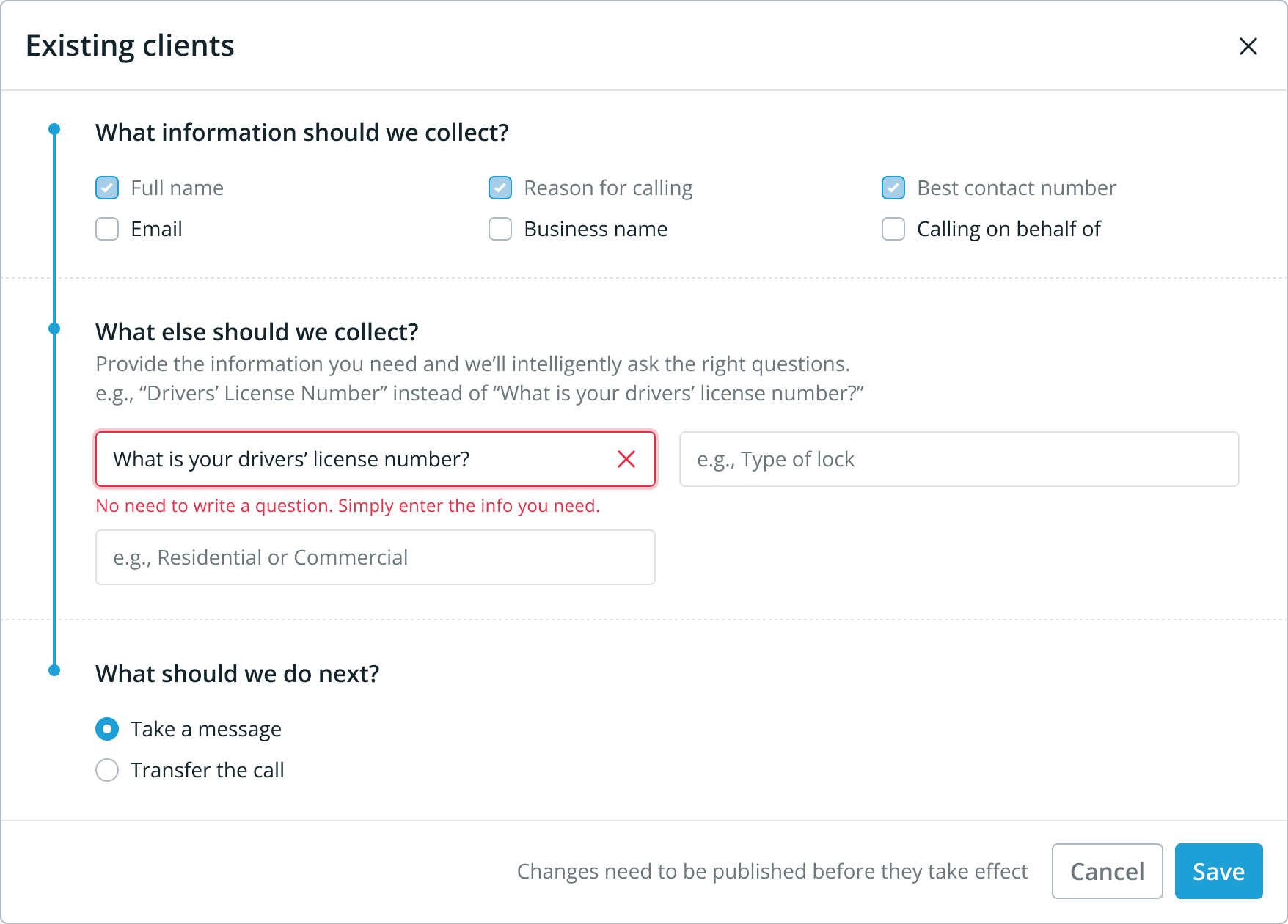
A good example is that, typically, customers want to ask specific questions of their callers but—through our testing—we discovered that writing explicit questions often resulted in a worse conversational experience.
To mitigate this we opted to only ask for the 'information' people needed but the initial design did not adequately set that expectation.
Customers tried to ask questions and ran into our character limit.
We learned about this pretty quickly and—using the strategy above—were able to learn about the expectations of users and how the interface differed from their mental models.
The solution was to reduce the friction for inputting information, give a real example of what is expected vs common, and to write some smart validation rules when someone still tries the common behaviour.
Pitfalls of LLMs
One of the most significant issues with large language models (LLMs) is their non-deterministic nature. When you ask the same question multiple times, the AI may generate different responses. This posed a challenge during development and QA, as it was difficult to predict exactly how the assistant would behave in every situation.
To address this, we developed an internal AI testing suite that simulated multiple conversations between the AI assistant and a synthetic AI caller. This allowed us to capture a range of possible responses, ensuring that the assistant remained on-brand and helpful even when generating different outputs for the same input.
Another key challenge was AI hallucinations, where the assistant would confidently deliver inaccurate information if it lacked proper data. We mitigated this by tightly controlling the data sources and creating fallback mechanisms. For instance, when the assistant didn’t have the correct data, it was trained to respond with a clarification or to defer to human input, rather than guessing.
Low-latency as a feature
Low-latency response times were crucial to the success of our voice assistant, especially in real-time phone conversations where delays can lead to a frustrating user experience. To address this, we optimized our backend infrastructure to minimize processing time, ensuring that the AI responded as quickly as possible.
We prioritized latency reduction across all services, from API response times to telephony integration, so that the assistant could handle conversational turn-taking naturally. As part of this effort, we used load balancing and cloud-based edge servers to reduce latency for customers in different regions.
Future
Using the feedback loop and prioritisation tools, there are already lots of improvements and features on their way.